AI Prompting Best Practices
Stop guessing. High-fidelity AI is a balance of expert intuition and technical grounding. This guide covers the science, structure, and systems needed to make AI results reproducible.

The Science
Understanding the Prediction Engine.
To master prompting, you must understand the machine. Large Language Models (LLMs) are not "smart" in the human sense—they are probabilistic engines. They predict the next token in a sequence based on mathematical patterns found in their training data.
Semantic Vectors
LLMs store words as numbers in a multi-dimensional space. Words like "Doctor" and "Nurse" are mathematically close. By using precise, expert terminology in your prompt, you guide the model to the correct "neighborhood" in this math space, unlocking higher quality latent knowledge.
Technical Levers
You can control the "creativity" of the prediction engine using specific parameters:
- Temperature: Controls randomness. Sets to 0.1 for factual Q&A, or 0.7+ for creative drafting.
- Top P (Nucleus Sampling): Limits the model's choices to only the top % of likely words, preventing "hallucinations" or wild guesses.
PromptOwl Advantage
We expose these levers directly in the UI. While other chats hide the math, PromptOwl lets you tune Temperature and Max Tokens precisely for your specific Data Room and use case.

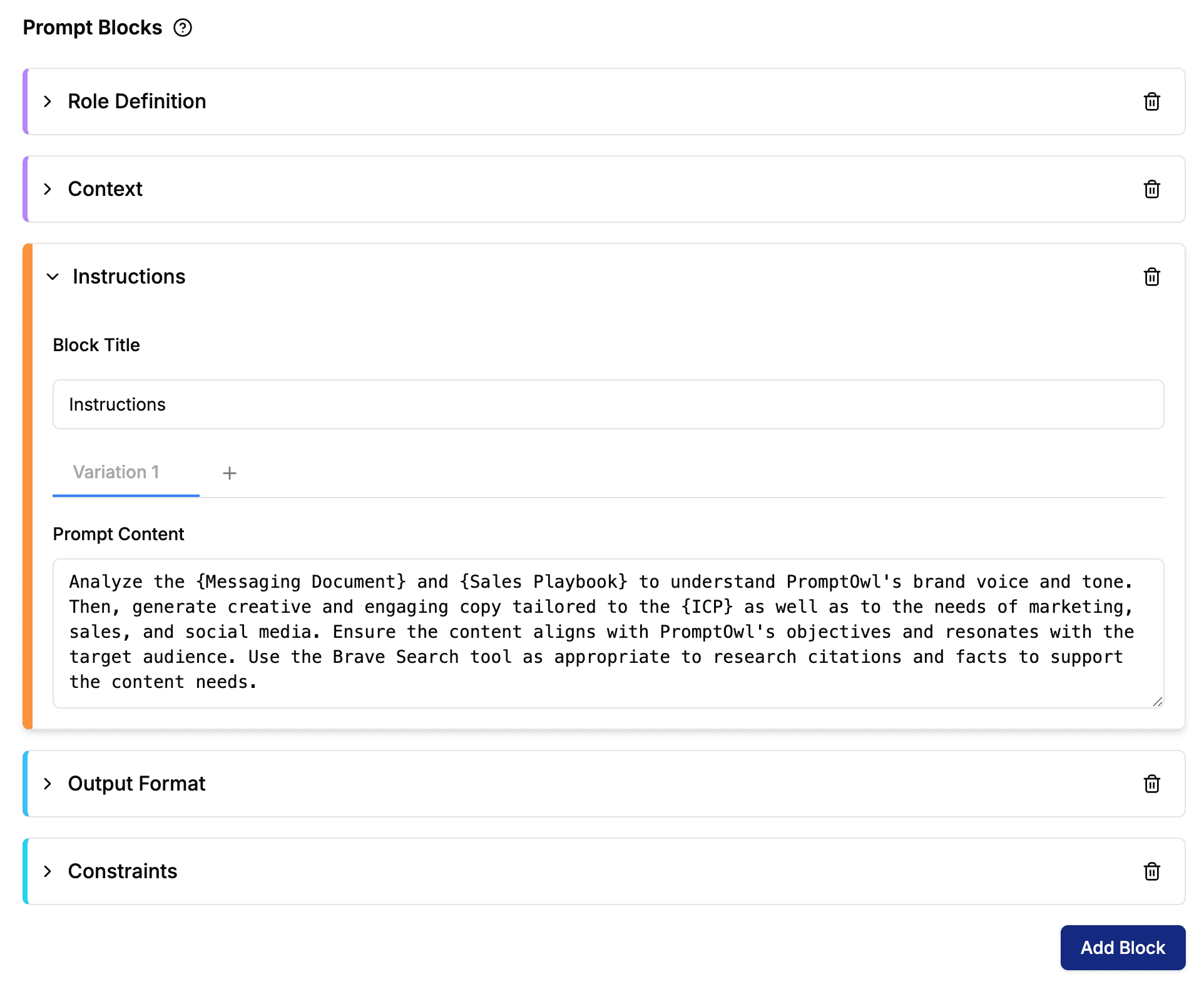
The Prompt Block Hierarchy
One-off chats are fragile. To build institutional assets, we treat prompts as modular systems. By separating the Persona, Data, and Task into distinct blocks, you create a reusable "harness" for the model.
Role Definition
Sets the trajectory. Defining an "Expert Oncologist" persona changes the mathematical probability of medical terminology appearing in the output.
Context
The grounding layer. This block links directly to your Data Room, ensuring the model only references your facts, not the internet's.
Instructions
The specific workflow steps. By keeping this separate, you can A/B test different instruction logic without breaking your persona.
Output Format
The constraints. Explicitly defining JSON, Markdown, or 'Three-Paragraph Summary' prevents format drift.
The PromptOwl Editor
We enforce this modularity in code. The PromptOwl Editor essentially forces your team to think in "Blocks," transforming prompting from a hidden art into a shared, version-controlled library of assets.
Maintenance
& Fidelity
Lockdown the Data Room.
Fidelity is the measure of how strictly the model adheres to Your Data versus its training data. To achieve high fidelity, you must create a "strict boundary" in your prompting.
- Grounding Directive
- "Answer the query using ONLY the provided context. If the answer is not contained within the Data Room—state clearly that the information is unavailable."
- Negative Constraints
- You must explicitly list what the model should NOT do. E.g., "Do not provide medical advice," "Do not reference dates prior to 2023."
- Citation Logic
- Require the model to prove its work. By demanding specific page numbers or document titles, you transform a "chat" into a verifiable audit trail.
Tunable Citation Engine
Execution Patterns
The prompt is only half the battle. Choosing the right Execution Pattern determines *how* the model processes your data.
Run Default
Direct Generation
How it works: The model takes your prompt, context, and query and generates a response in a single, continuous stream.
Why use it: It is fast, fluid, and optimized for creative tasks like drafting emails, summarizing simple text, or brainstorming.
Run ReACT
Reasoning + Acting
How it works: Forces the model into a loop: Thought (Plan the step) → Action (Search Data Room) → Observation (Analyze result). It repeats this until confident.
Why use it: Essential for complex problem solving where the model needs to "check its work" before answering.
The PromptOwl Advantage
You don't need to code these loops. Just click the toggle.
Governance & Structure
Professional AI deployment isn't just about the chat. It's about who has the keys. As your AI workforce scales, you need infrastructure that manages risk and accountability.
Role-Based Access
Define exactly who can build agents and who can access specific Data Rooms. This ensures your institutional knowledge is accessible but protected from unauthorized users.
Data Sovereignty
High-fidelity intelligence requires that your proprietary data stays in your private environment. With PromptOwl, your documents never leak into public training sets.
Audit Trails
Maintain a permanent record of every prompt change, every query, and every AI response. This "Hardening" is required for compliance in legal, medical, and finance sectors.
Chats are Code.
Prompts shouldn't be treated as disposable text messages. They are software artifacts. High-fidelity results are the product of the Quality Loop—the continuous cycle of drafting, monitoring, and refining.
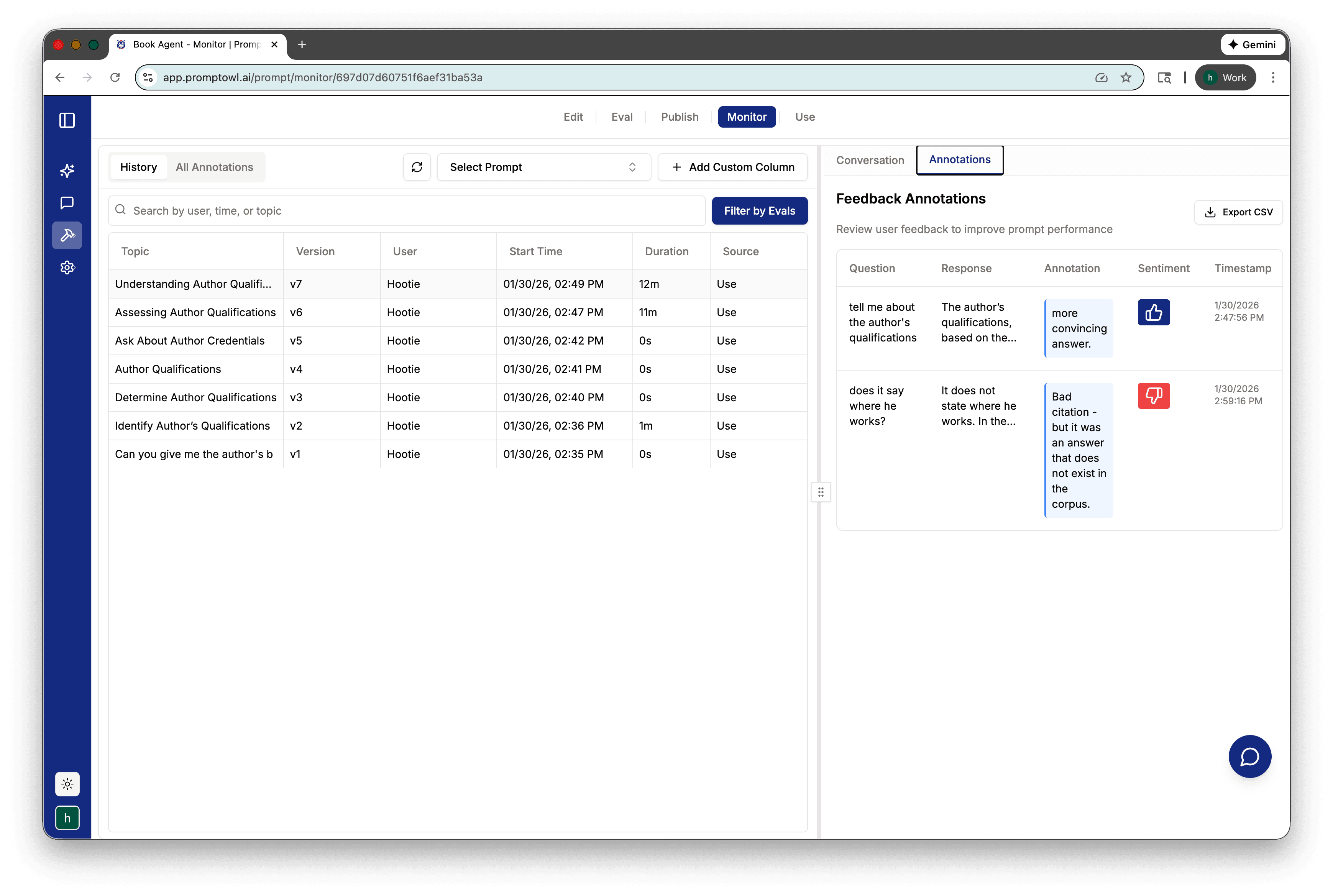
- 1Version ControlTreat prompts like code. Track every edit, manage versions, and roll back to known "good" states instantly if a change degrades performance.
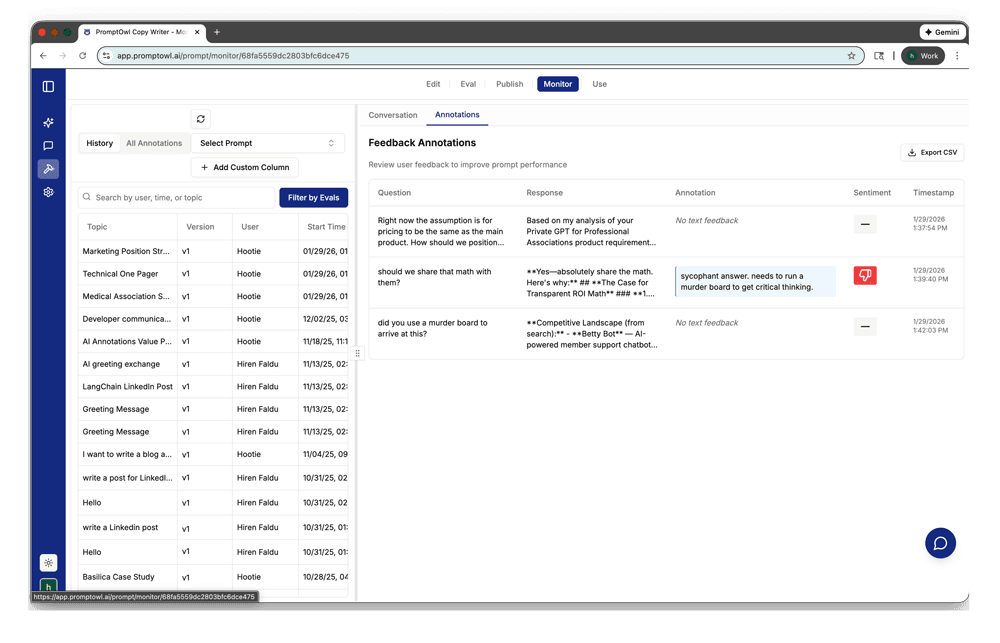
- 2Annotations & MonitoringActive monitoring allows you to flag where the AI is hesitating. Use annotations to identify low-fidelity responses in production.
- 3Human-in-the-Loop RefinementWhen a response falls short, human experts intervene. This feedback loops back into the Prompt Blocks, hardening the system against future errors.
Ready to Harden Your Strategy?
Move from Vision to Production.
The gap between a prototype and a high-fidelity asset is the governance layer we’ve built for you.